目标检测数据集制作
概要
数据集的构建,应该使用“少量标注+半自动标注”的方式,即先标注少量数据,然后通过「半自动标注」的方式,快速标注其他数据,最后通过标注工具进行精细化调整。这样可以大大减少标注的工作量
因此建议先阅读完整个文档,再构建自己的数据集
数据集采集和归档
TIP
数据是比代码更重要的资产,因此不要放置在项目内
将数据集放入如下目录
DATASET_DIR=/path/to/dataset需要注意的是,数据集通常需要放置在项目外的路径,例如
~/data或$HOME/data(推荐)(win 下为$env:USERPROFILE/data)。如果放置在项目内,导致编辑器对于项目的索引过大,会导致编辑器卡顿
这里准备好了一个示例数据集,可以下载,并保存在 ~/data/drink 目录下
wget -P ~/data https://github.com/HenryZhuHR/deep-object-detect-track/releases/download/v1.0.0/drink.tar.bz2
tar -xf ~/data/drink.tar.bz2 -C ~/data
cp -r ~/data/drink ~/data/drink.unlabel
rm -rf ~/data/drink.unlabel/**/*.xml为了方便可以在项目内建立软链接,软链接不会影响编辑器进行索引,但是可以方便查看
ln -s ~/data resource/data随后可以设置数据集目录为
DATASET_DIR=~/data/drink考虑到单张图像中可能出现不同类别的目标,因此数据集不一定需要按照类别进行划分,可以自定义划分,按照项目的需求任意归档数据集,但是请确保,每一张图像同级目录下有同名的标签文件。可以参考如下的几种目录结构构建自己的数据集:
# 这种目录结构适用于数据集不划分类别,直接存放在同一目录下
·
└── /path/to/dataset
├─ file_1.jpg
├─ file_1.xml
└─ ...# 这种目录结构适用于数据集按照类别划分,每个类别一个目录
·
└── /path/to/dataset
├── class_A
│ ├─ file_A1.jpg
│ ├─ file_A1.xml
│ └─ ...
└── class_B
├─ file_B1.jpg
├─ file_B1.xml
└─ ...# 这种目录结构可以根据项目的需求自定义划分,例如按照视频分割帧构建的数据集
·
└── /path/to/dataset
├── video_A
│ ├─ file_A1.jpg
│ ├─ file_A1.xml
│ └─ ...
└── video_B
├─ file_B1.jpg
├─ file_B1.xml
└─ ...启动标注工具
使用 labelImg 标注,安装并启动
pip install labelImg
labelImg在 Ubuntu 下启动后的界面如下(Windows 版本可能略有差异) 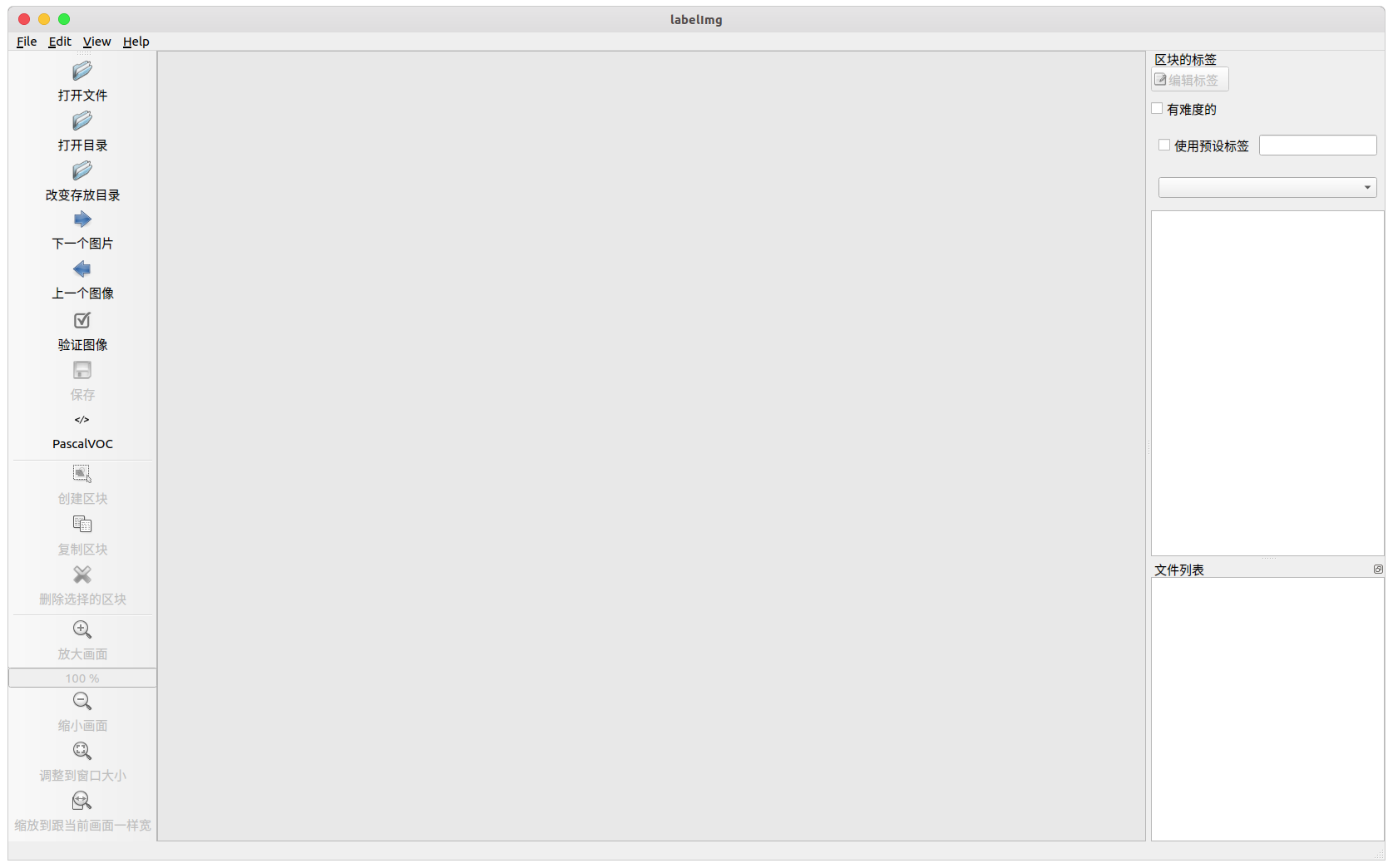
- 打开文件 : 标注单张图像(不推荐使用)
- 打开目录 : 打开数据集存放的目录,目录下应该是图像的位置
- 改变存放目录: 标注文件
.xml存放的目录 - 下一个图片:
- 上一个图像:
- 验证图像: 验证标记无误,用于全部数据集标记完成后的检查工作
- 保存: 保存标记结果,快捷键
Ctrl+s - 数据集格式: 选择
PascalVOC,后续再转化为YOLO
点击 创建区块 创建一个矩形框,画出范围 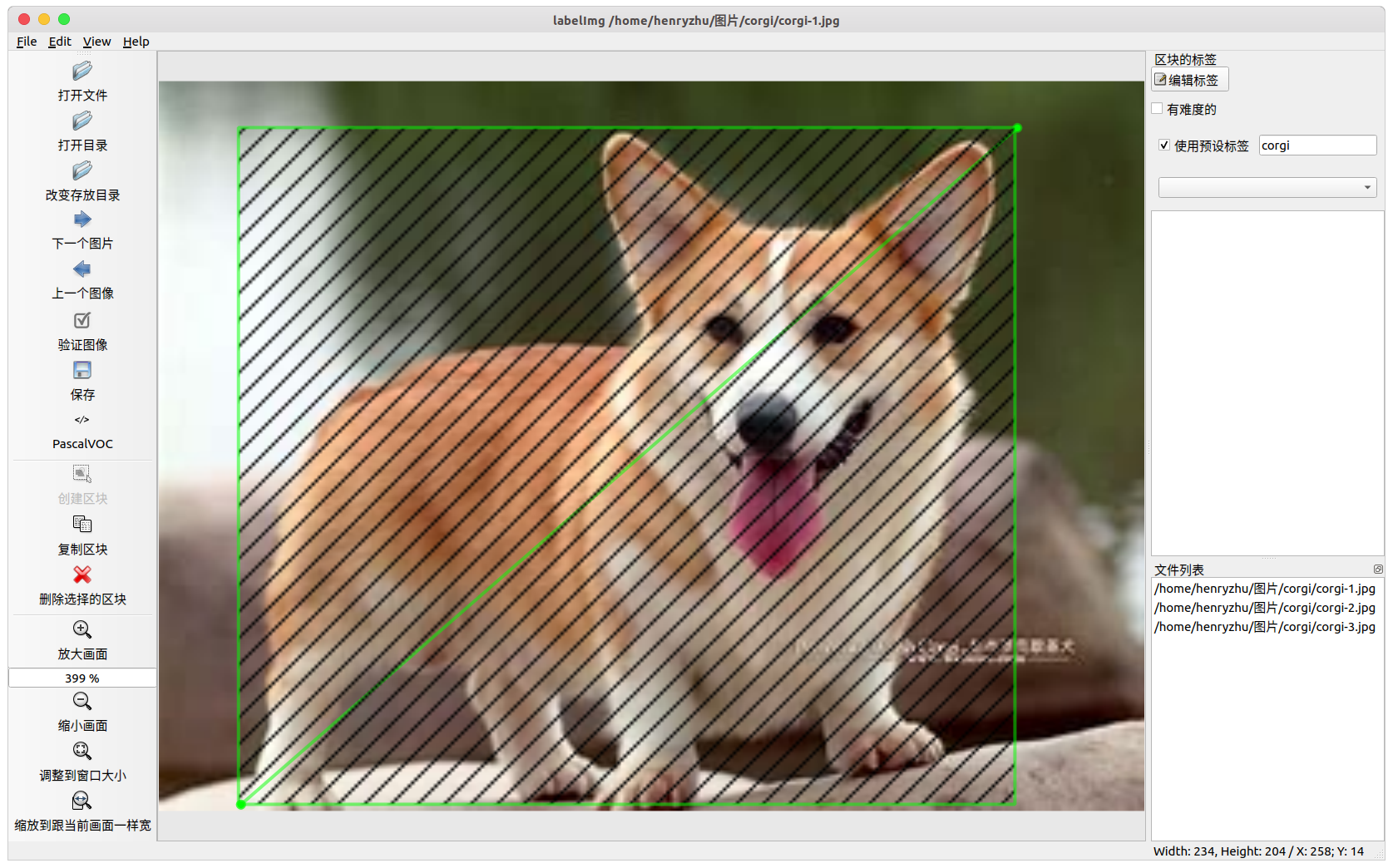
每个类别都有对应的颜色加以区分 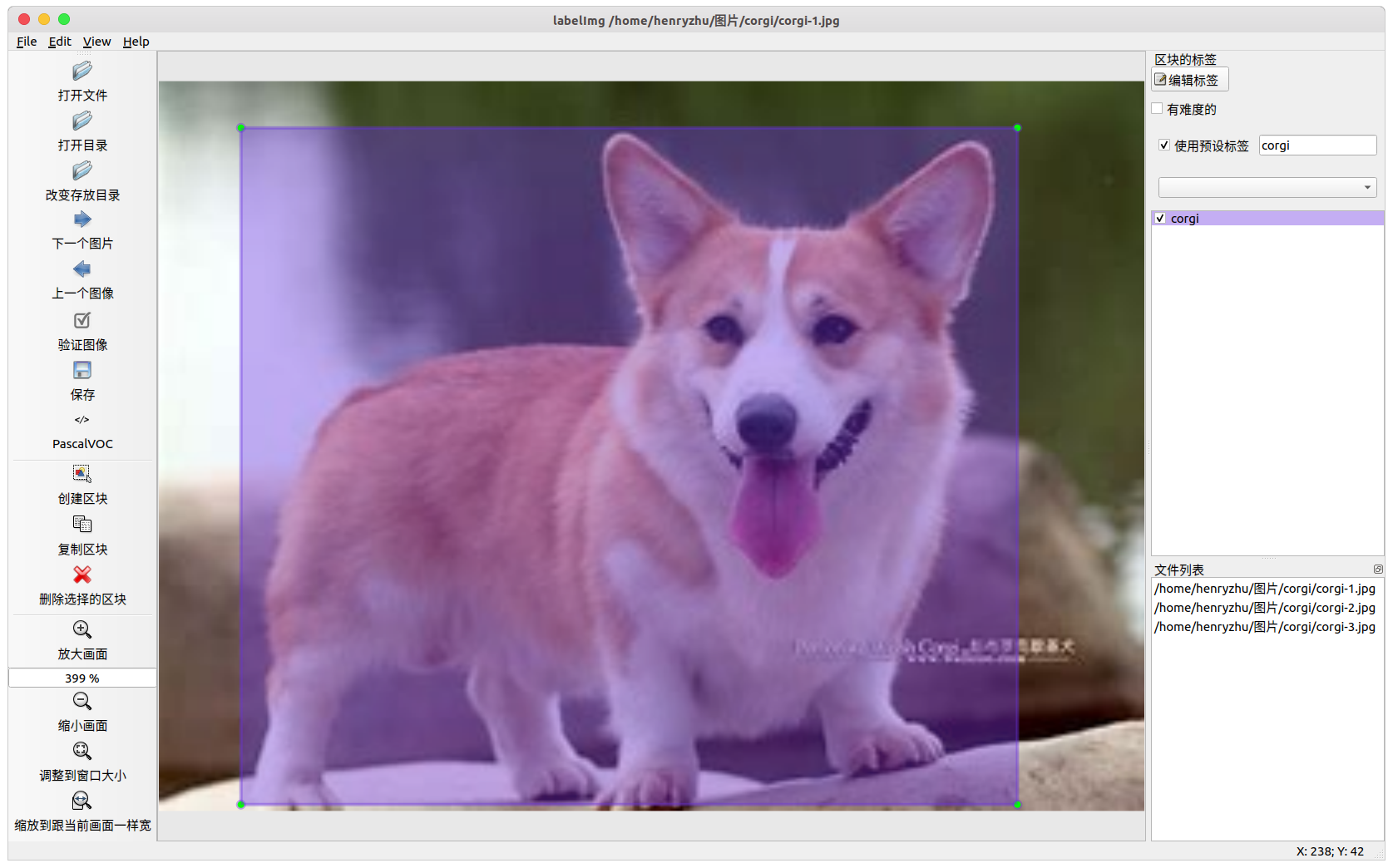
完成一张图片的标注后,点击 下一个图片
- labelImg 快捷键
| 快捷键 | 功能 | 快捷键 | 功能 |
|---|---|---|---|
| Ctrl+u | 从目录加载所有图像 | w | 创建一个矩形框 |
| Ctrl+R | 更改默认注释目标目录 | d | 下一张图片 |
| Ctrl+s | 保存当前标注结果 | a | 上一张图片 |
| Ctrl+d | 复制当前标签和矩形框 | del | 删除选定的矩形框 |
| space | 将当前图像标记为已验证 | Ctrl+ | 放大 |
| ↑→↓← | 键盘箭头移动选定的矩形框 | Ctrl– | 缩小 |
数据处理
运行脚本,生成同名目录,但是会带 -organized 后缀,例如
python dataset-process.py -d ~/data/drink # -d / --datadir建议路径不要有最后的
/或者\,否则可能会出现路径错误
该脚本会自动递归地扫描目录 ~/data/drink 下的所有 .xml 文件,并查看是否存在对应的 .jpg 文件
TIP
因此,你可以不必担心目录结构,只需要确保每张图像有对应的标签文件即可,也不必担心没有标注完成的情况,脚本只处理以及标注完成的图像
生成的目录 ~/data/drink-organized 用于数据集训练,并且该目录为 yolov5 中指定的数据集路径
数据自定义处理
TIP
通常来说不需要自定义处理,只需要遵循上述的规则即可快速创建数据集,但是如果需要,可以参考下面提供的接口
如果不需要完全遍历数据集、数据集自定义路径,则在 get_all_label_files() 函数中传入自定义的 custom_get_all_files 函数,以获取全部文件路径,该自定义函数可以参考 default_get_all_files()
def default_get_all_files(directory: str):
file_paths: List[str] = []
for root, dirs, files in os.walk(directory):
for file in files:
file_paths.append(os.path.join(root, file))
return file_paths并且在调用的时候传入该参数
# -- get all label files, type: List[ImageLabel]
label_file_list = get_all_label_files(args.datadir)
label_file_list = get_all_label_files(
args.datadir,
custom_get_all_files=default_get_all_files
) 半自动标注
训练完少量数据集后可以使用 auto_label.py 脚本进行半自动标注
该脚本需要使用 OpenVINO 的模型进行推理,因此参考 导出模型 导出 openvino 模型,主要修改 EXPORTED_MODEL_PATH 为导出的模型路径和 数据集配置 DATASET_CONFIG ,然后注释导出命令 python3 export.py ... --include onnx 和 python3 export.py ... --include engine
bash scripts/export-yolov5.sh查看 auto_label.py 参数设置,然后执行
python auto_label.py如果已经被标注,会提示 If you want to re-label, please delete it by 'rm ~/data/drink.unlabel/cola/cola_0000.xml' 的信息防止已经被标注的数据被覆盖,如果希望删除全部,可以用正则表达式
rm -rf ~/data/drink.unlabel/**/*.xml随后可以用 LabelImg 进行检查和精细化调整
labelImg ~/data/drink.unlabel